Spotify Playlist Enhancer
The goal of this project is to suggest my liked Spotify tracks to my playlists, with the aim of enhancing my playlists with tracks I may have missed.
TL;DR
- Neural net works best
- Oversampling produced artificially high scores but poor predictions, manually setting class weights works much better.
- The algorithm performed well overall, with mistakes restricted to misclassifications that are human-like in nature.
Data Gathering
I used Spotipy to build two separate dataframes. The first consists of all tracks from each playlist I have created, along with audio features such as loudness, danceability, energy, and duration, along with the playlist and artist titles.
This “playlist_df” had 2417 songs in total, with 2055 unique songs.
The second dataframe contains the same audio features and artist name for each track in my liked songs (667 total unique songs).
The first dataframe is used as training data for the algorithm, with the audio features acting as training labels and the target label being the playlist name. This allows the algorithm to learn the general vibes of the tracks inside each playlist.
Exploration
The playlist dataframe is highly imbalanced, with 37% of the tracks being located within the three largest playlists.
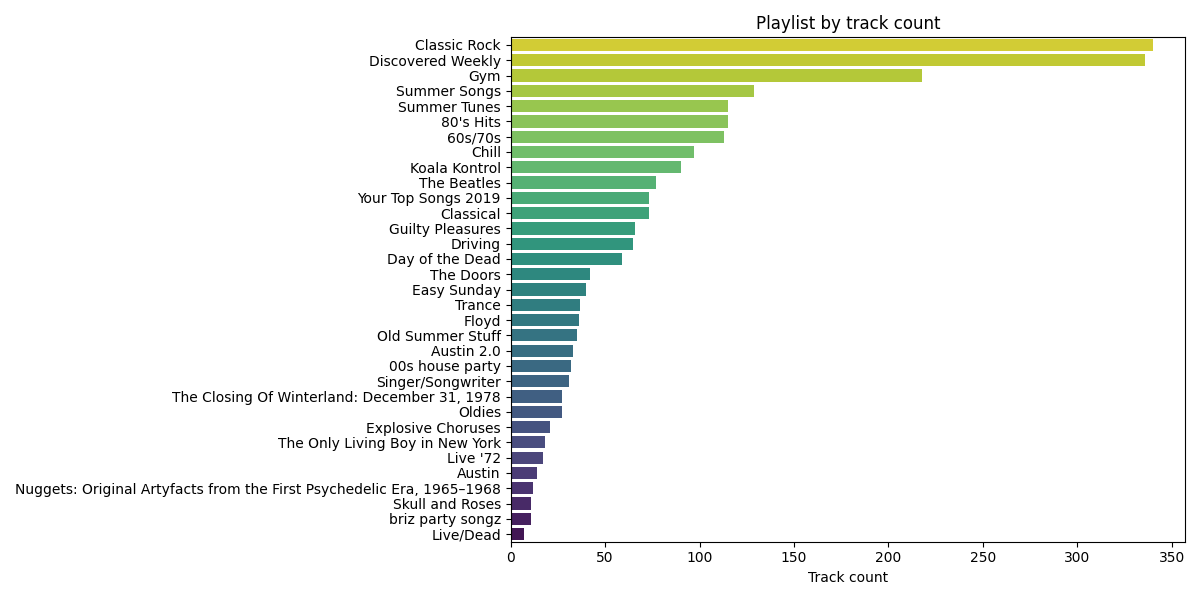
In order to create a useful algorithm that doesn’t just predict that every songs fits into either “Classic Rock”, “Discovered Weekly” or “Gym”, this imbalance must be handled during preprocessing.
Weight and Biases
I used Weights and Biases (WandB) to track various configurations, this allowed for easy graphical tracking of each run’s configuration and final metrics.
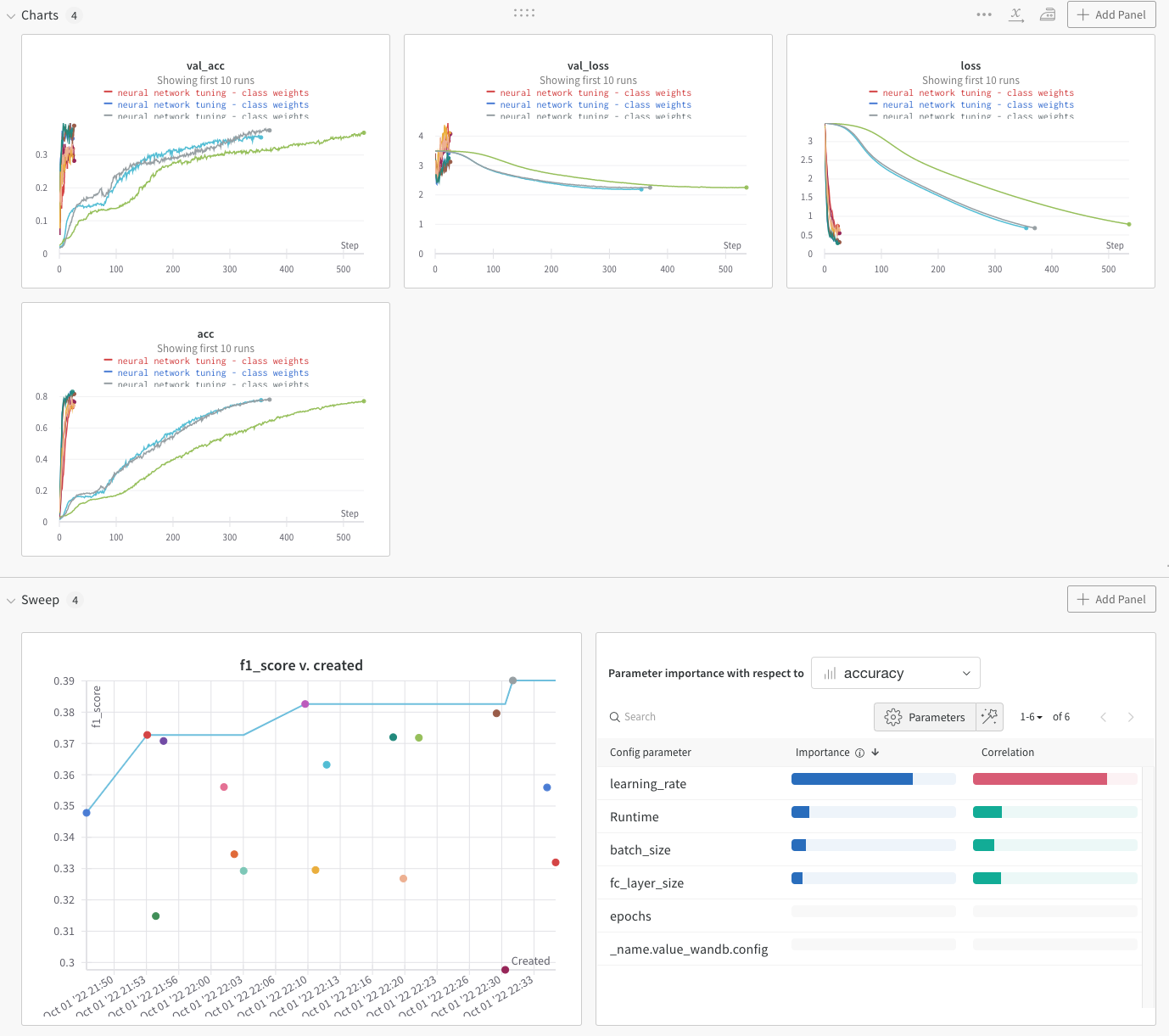
Accuracy was used in conjunction with F1 score to determine the best configuration, from:
- Different transformation techniques:
- MaxAbs Scaler, Robust Scaler, One hot encoding, removal of categorical features
- Different algorithms:
- KNN, XGBoost, Logistic Regression, Neural Networks
- Hyperparameter tuning for each algorithm.
Preprocessing
Two different techniques for handling the imbalanced data were tried: Oversampling and class weights. Oversampling provided higher accuracy and F1 scores, however predictions were highly skewed to the training playlists with a high volume of tracks - showing the imbalance was still a problem.
Class weights resulted in lower scores but seemed to help the imbalance problem.
I wanted to maintain the artist’s name as a feature in each track, however doing so meant that the data had relatively high cardinality. Ordinal encoding doesn’t make sense here, and although hashing may be useful I decided to just try one hot encoding and see how well the algorithm performs.
In order to test transformation techniques, I ran logistic regression and XGBoost models with default hyperparameters and recorded the best configuration - Max abs scaler with one hot encoding.
Modelling
After the highest scoring preprocessing transformation techniques were discovered hyperparameter sweeps for the different algorithms were undertaken:
| No. | Name | Accuracy Score | Link |
|---|---|---|---|
| 1 | Logistic Regression - Oversampling | 0.87 | Link |
| 2 | XGBoost - Oversampling | 0.88 | Link |
| 3 | KNN - Oversampling | 0.83 | Link |
| 4 | Neural Network - Oversampling | 0.94 | Link |
| 5 | Logistic Regression - Class Weights | 0.38 | Link |
| 6 | XGBoost - Class Weights | 0.33 | Link |
| 7 | Neural Network - Class Weights | 0.39 | Link |
As discussed above, oversampling produced artificially inflated scores, with the models predicting most tracks into the top three playlists regardless of their features.
Therefore the final best model was a neural network with class weights manually adjusted to account for the training dataset imbalance. The best performing neural net consisted of 5 layers of 128 neurons, with a 0.001 learning rate, and a batch size of 32. It ran for approximately 50 epochs before early stopping.
Validation accuracy can be seen below.
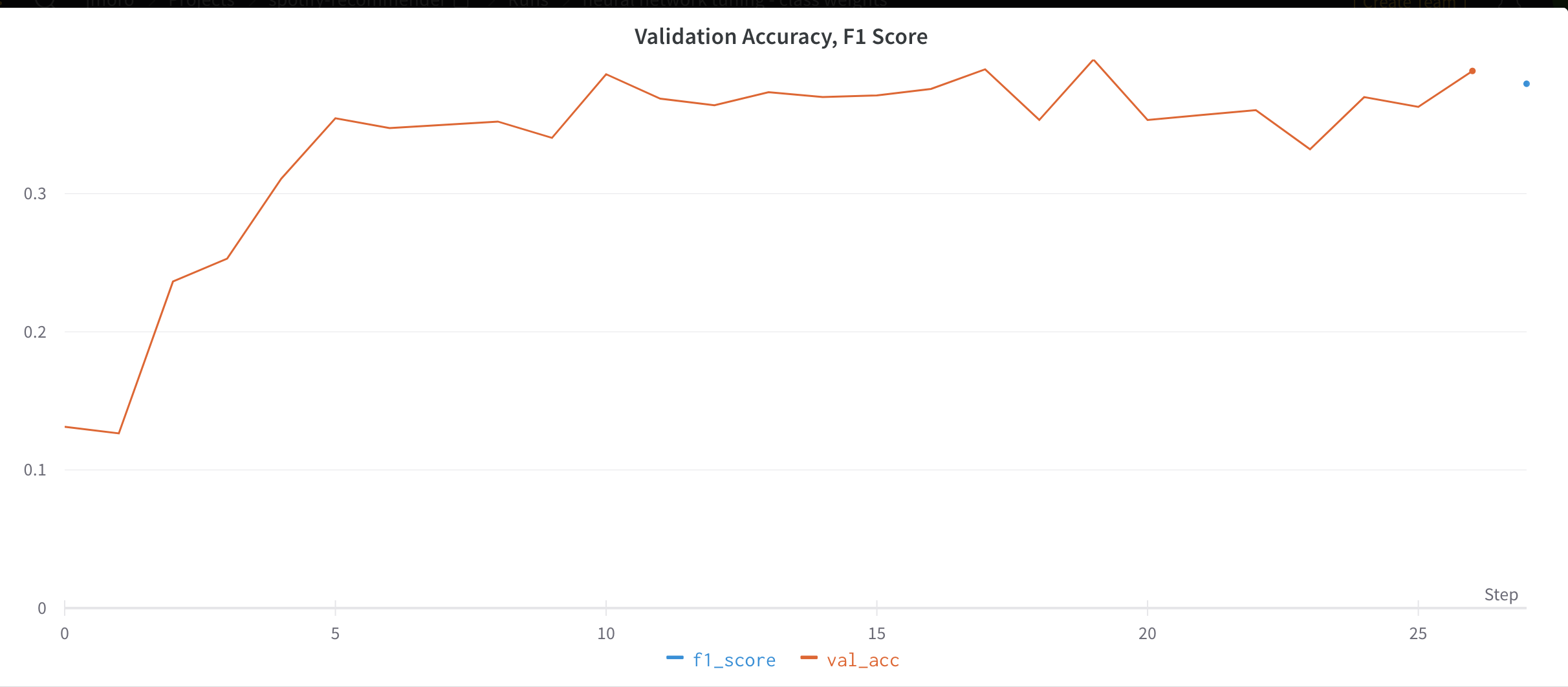
Here, F1 score is calculated at the end of the training and not per epoch therefore consists of only 1 point.
WandB also provides an estimation of the most important training features:
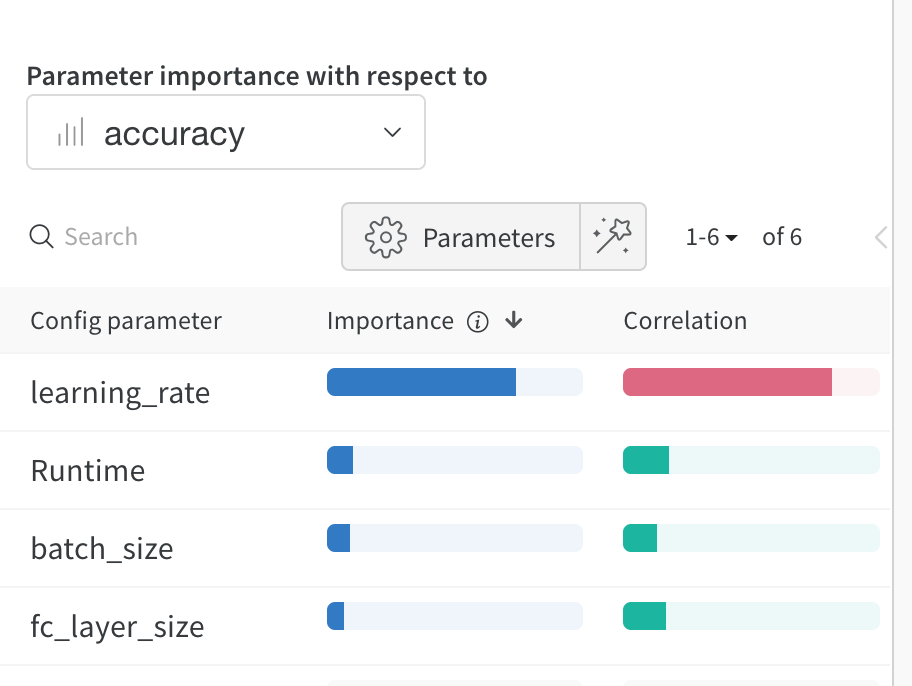
Here, learning rate is by far the most important feature. The red bar graph means there is an inverse correlation -> lower LR means higher accuracy.
Predictions
Commentary on the final predictions can be found in the modelling/prediction_exploration notebook.
Generally the net performed well on the liked song dataset, with most of the highest confidence predictions fitting nicely into sensible playlists.
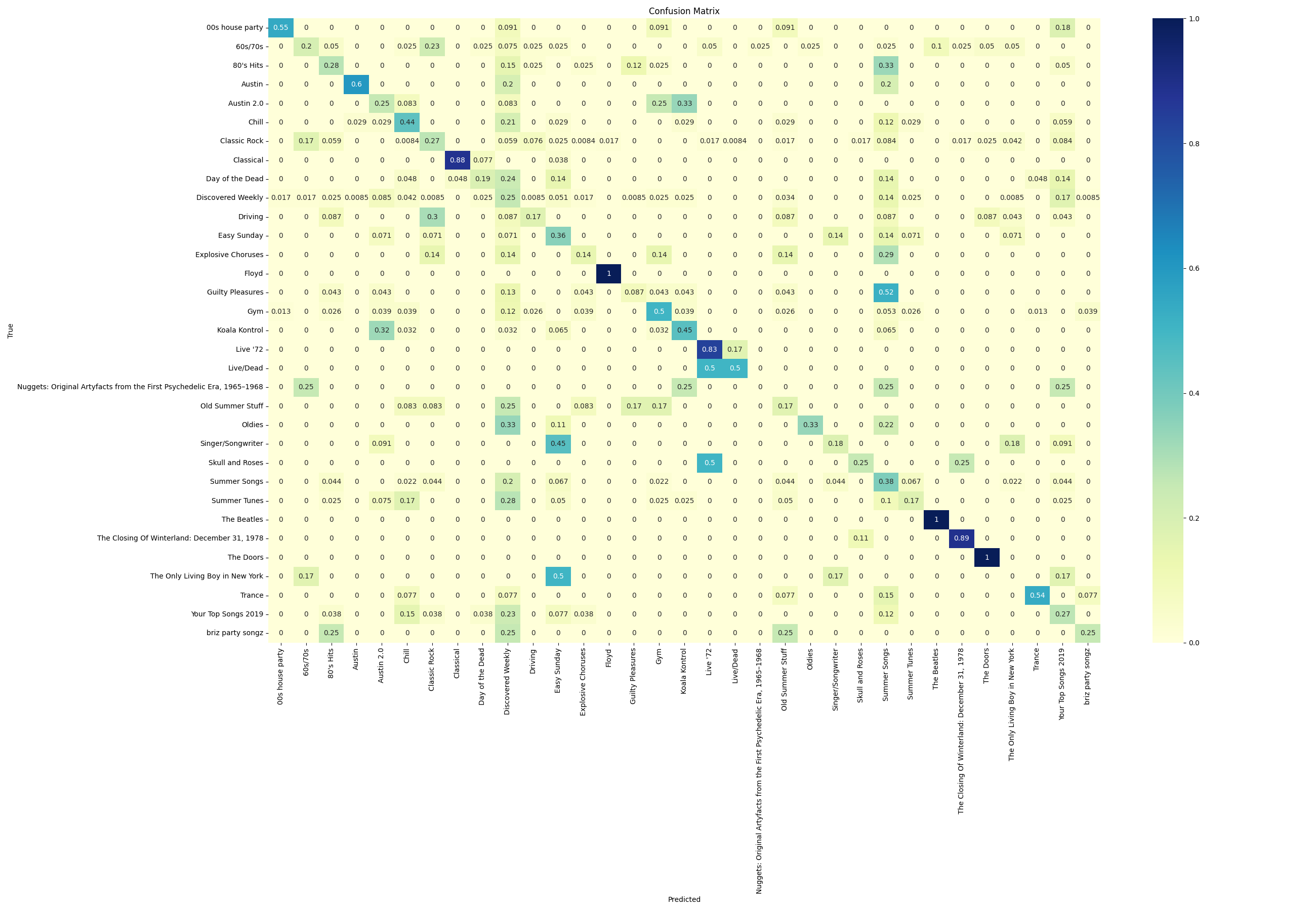
The confusion matrix shows the most common mistakes are ones that even a human would likely make, such as mixing up two acoustic-heavy playlists.
Reassuringly, the playlists that consist of only a single artist consistently scored extremely high.
Overall the algorithm performed well and definitely helped me bulk out some of my playlists with songs I know I enjoy.
Next steps
- Try hashing as a transformation technique
- Make available for other users - however the performance would be entirely dependent on their playlist style, quantity of playlists, and quantity of songs per playlist.
- Include track year as a training feature, as some playlists are skewed towards certain eras.
