

All the source code for this project can be found on my github.
Checkout the final streamlit recommendation app here!
I previously attempted to create a podcast episode recomendation app with latent dirichlet allocation (link), although an interesting learning experience the final results were not as impressive as i would’ve liked. Therefore I decided to re-implement the solution using an open source sentence transformer - all-MiniLM-L6-v2 and ChromaDB vector database, with much improved results.
The “Stuff You Should Know” (SYSK) podcast is a popular educational and informative podcast series that explores a wide range of topics, providing listeners with interesting and often quirky insights into various subjects. It is hosted by Josh Clark and Chuck Bryant.
This app allows users to search the SYSK podcasts for episdodes that interest them, for example episodes on American History, Fast Food, or Unsolved Mysteries. It uses semantic search to return episodes based on context rather than keyword search, for example ‘Airplanes’ returns among others, “Turbulence” - an episode that may not show up with keyword search.
Data Stats
- Dataset consists of 2044 episodes in total
- Average length of transcript: 35,485 words
- Total of 72,531,340 words in the entire corpus
How to use
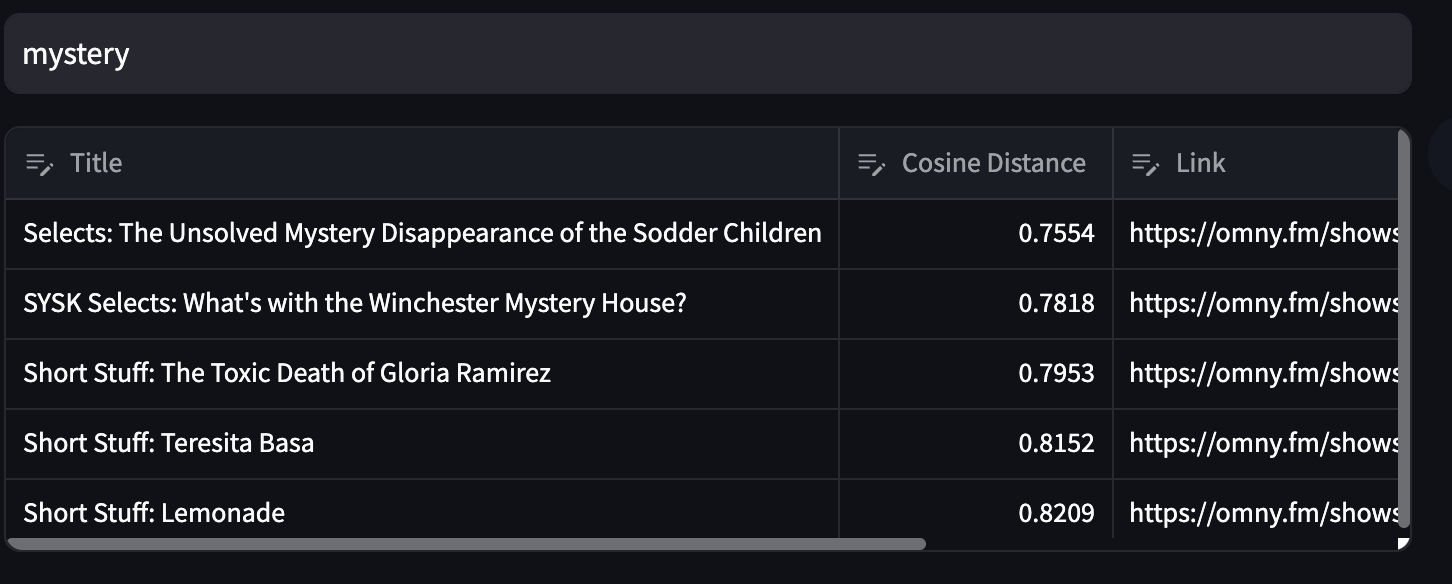
The search seems to work best with short phrases or single keywords, for example the search for mystery produces good results:
How I built this
Transcript storage
I first use pandas to read the provided parquet files and subsequently write them to a local postgresql database. Storing the files in a database allows for easy access for the remainder of the project.
Text Preprocessing
Preprocessing is generally the most important and labour intensive part of natural language processing and in broader machine learning and this project is no exception. I used two popular NLP packages to undertake preprocessing: spacy and nltk. This involved:
- Removing stopwords and punctuation. I append my own custom stopwords (contained in “custom_stopwords.txt”) to spacy’s built in stopwords. These custom stopwords generally consist of common SYSK sponsors, and Josh and Chuck’s full names.
- Lemmatization. I use NLTK’s WordNetLemmatizer to reduce the words to their lemmas.
Notably the preprocessing was much less intensive than the previous LDA modelling.
ChromaDB and word embeddings
The real magic is built into the ChromaDB. I use this library to encode each episode into numerical representations of the text. Under the hood this uses the free and open source all-MiniLM-L6-v2 sentence transformer.
The embeddings are stored in a sqlite3 db file for easy retrieval and querying.
Streamlit App
In order for a prediction model to be useful, it has to be accessible to users. For this I decided to use Streamlit, a simple easy to use hosting web app package which includes hosting.
The app embeds the search text, and queries the sqlite3 file to return the 5 most closely related episodes.
I decided to use the cosine distance metric to determine similarity, therefore a lower score corresponds to a better match.
Bugs and Hurdles
I ran into a few issues getting running, mainly around the Streamlit deployment.
-
The ChromaDB library requires access to the sqlite3 file to query, however this file is over the github file size limits. I got around this by using git large file system (LFS) but getting the system up and working was not obvious.
-
The version of sqlite3 included with Streamlit is outdated, and ChromaDB required a newer version. This was solved by adding a
pysqlite3-binaryrequirement to myrequirements.txtfile, and by following the advice in this stack overflow post. -
Usual streamlit + poetry issues. Streamlit doesnt seem to work nicely with poetry’s
pyproject.tomlfile. By exporting the toml to “normal”requirements.txtseemed to get Streamlit up and running.
- Pierson, B. D. (2022, July 30). “Stuff You Should Know” Podcast Transcripts - Full Dataset with Transcript of All Episodes (SYSK_Transcripts). https://doi.org/10.17605/OSF.IO/VM9NT
